Big Data & Issues & Opportunities: Trust, Surveillance and Free Will
When big data technologies were first being developed, they were mainly deployed in the sphere of marketing. As such, their use was both lucrative and low-risk. However, as soon as big data technology moved beyond increasing the odds of making a sale to being used in higher-stakes decisions like medical diagnosis, loan approvals, hiring and crime prevention, more social and ethical implications arose.
In the final three articles in our series on "Big Data & Issues & Opportunities" (see our previous article here), we examine certain ethical and social aspects of the use of big data. This fifteenth article notably looks into the concepts of trust, surveillance and free will in relation to big data. Where appropriate, illustrations from the transport sector are provided.
Trust
The Oxford English Dictionary defines trust as the "firm belief in the reliability, truth, or ability of someone or something". Trust as such is not recognised as a fundamental right in the EU Charter of Fundamental Rights. However, together with the concept of surveillance, it may be discerned in the right to liberty and security acknowledged by Article 6 of the Charter.
As explained in the first article of our series, one of the main dimensions of big data, describing consistency and trustworthiness, is veracity.[1] It is however quite difficult, if not impossible, to outline one general shared understanding of trust in relation to big data since the trustworthiness of information can change depending on whom we speak to, where the data is gathered, or how it is presented. [2]
Nevertheless, an important aspect of "trust" in relation to big data is trust as the result of the belief in the honesty of stakeholders in the process of collecting, processing, and analysing the big data. In this respect, veracity is in principle a moral requirement according to which big data users (collectors, analysts, brokers, etc.) should respect the individual citizen as a data provider, for instance, by facilitating his or her informed consent. The right not to be subject to automated decision-making or the right to information for individual citizens (as enshrined in the General Data Protection Regulation) seem to be under pressure when veracity, honesty and consequently trust are not upheld.[3]
Big data for trust & trust in big data
The idea behind 'big data for trust’ is to address questions of how to use big data for trust assessment (i.e. to measure trust). While the huge variety of big data may bring opportunities, it may also present challenges in relation to its quality (e.g. heterogeneous and unstructured data). One way to use 'big data for trust' is through so-called reputation systems. The general process of reputation systems can be separated into the following three steps: (i) collection and preparation; (ii) computation; and (iii) storage and communication. In the first step, data or information about the past behaviour of a trustee are gathered and prepared for subsequent computing. Today's vast number of web applications such as e-commerce platforms, online social networks or content communities has led to huge amounts of reputation data being created from big data. Among others, the need to integrate both explicit and implicit information has been highlighted.[4] To extract implicit reputation information from big data, most of data that is semi- or unstructured according to the variety property of big data, is handled to get the implicit information through natural language processing and machine learning. In the second step, both the explicit and implicit reputation information are used in the computation phase to calculate a reputation value as its output. This phase consists of filtering, weighting and aggregation processes and is concerned with the question of how relevant the information used is for the specific situation. Finally, the reputation values are combined to generate one or several scores. The final storage and communication step stores the predicted reputation scores and provides them with extra information to support the end users in understanding the meaning of a score-value. In this regard, we may encounter challenges about the reusability of reputation information and the transparency of communication.
'Trust in big data' is about measuring the trustworthiness and accuracy of big data to create high values of data which are coming in large volume and different formats from a wide variety of applications/interfaces. In this regard, analysing this valuable information is not as easy as it seems. There are tools available to extract and process this valuable information from disparate sources, but the real challenge is to know whether the data processed are trustworthy, accurate and meaningful.[5] With respect to the trust in big data, there are several trust issues as follows: (i) trust in data quality; (ii) measuring trust in big data; and (iii) trust in information sharing.[6] As mentioned above, verifying their trustworthiness and especially evaluation of the quality of the input data is essential due to the higher volume of data sources than ever before. In order to ensure the quality of input data, detecting manipulations of the data should be conducted before processing it.[7] To ensure data quality, several data mining approaches such as feature selection and unsupervised learning methods for sparsity, error-aware data mining for uncertainty, and data imputation methods for incompleteness have been studied[8] as well as the authentic synthetic data benchmarking of different big data solutions has been generated.[9]
Challenges and opportunities for big data and trust
To derive business value from non-traditional and unstructured data, organisations need to adopt the right technology and infrastructure to analyse the data to get new insights and business intelligence analysis. It can be feasible with the completeness, trustworthiness, consistency and accuracy of big data.
Dynamic technological developments where individuals do not have enough time to adapt, may lead to significant trust issues.[10] When it comes to mobility in the field of public transportation, safety and security are linked to trust: people need to feel safe when using transportation means which are new (e.g. self-driving cars) or which could be perceived as threatening (e.g. car-sharing with unknown drivers). As an example, gender or age perspectives could help in designing mobility-as-a-service, considering different needs in terms of easiness and sense of safety in public spaces.
|
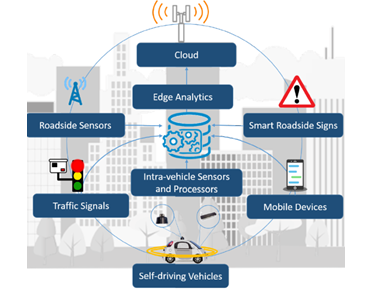
Illustration in the transport sector: Intelligent transportation systems ("ITS") are arguably the most anticipated smart city services.[11] Ferdowsi et al. proposed an edge analytics architecture for ITS in which data is processed at the vehicle or roadside smart sensor level to overcome the ITS reliability challenges.[12] The architecture is illustrated below.
Figure: ITS edge analytics architecture and components The proposed ITS edge analytics architecture exploits deep learning techniques running at the level of passengers’ mobile devices and intra-vehicle processors to process large datasets and enable a truly smart transportation system operation. This architecture improves the performance of ITS in terms of reliability and latency. This example also presents a transparent way of big data collection and the immediate use of processed data in traffic management. |
Surveillance
The Oxford English Dictionary describes surveillance as "close observation, especially of a suspected spy or criminal". In the context of this article, however, the term surveillance will be used to describe the close observation of all humans in general, irrespective of their criminal tendencies. In light of the EU Charter of Fundamental Rights, surveillance can be linked to Article 6 on the right to liberty and security, Article 7 on the respect for private and family life, and Article 8 on the protection of personal data.
In a big data context, surveillance is said to have the following six key characteristics[13]:
- Tracking is “populational”: big data has as a result that tracking relates to a group of people rather than being targeted at specific individuals.
- Correlation and predictability are no longer needed: when the necessary conditions are fulfilled, big data analytics can provide a reliable and veracious outcome, thus rendering the drawing of assumptions on the basis of correlation and predictions redundant.
- Monitoring is pre-emptive: in an analysis of the simulation of surveillance it was noted that the goal of predictive analytics is not simply to predict outcomes, but to devise ways of altering them. In policing terms, the goal of predicting the likelihood of criminal behaviour is to deter it.[14]
- Tracking is interventionist: in the future, we can expect that predictive analytics will become more sophisticated and will be deployed across a broad range of social life to shape and sort consumer behaviour and opportunities.
- All information is relevant: because predictive analytics is, as it were, model-agnostic, it does not rule out in advance the relevance of any kind of information.
- "Privacy" is irrelevant: any attempt to build a protective bulwark against big data surveillance on the foundation of privacy must confront the fact that much of the tracking is anonymous.
Challenges and opportunities for big data and surveillance
Two main issues arise in relation to surveillance, notably (i) risks of asymmetries in the control over information; and (ii) privacy.
The first issue points to the availability of big data giving a competitive advantage to those who hold the data in terms of capability to predict new economic, social, and political trends. The information and knowledge deriving from big data is not accessible to everyone, as it is based on the availability of large datasets, expensive technologies and specific human skills to develop sophisticated systems of analyses and interpretation. For these reasons, governments and big businesses are in the best position to take advantage of big data: they have large amounts of information on citizens and consumers and enough human and computing resources to manage it.[15]
When it comes to the privacy issues, the shift from targeted to 'populational' monitoring is facilitated by the advent of interactive, networked forms of digital communication that generate easily collectible and storable meta-data.[16] However, the logic is self-stimulating and recursive: once the switch to an inductive, data-driven form of monitoring takes place, the incentive exists to develop the technology to collect more and more information and to “cover” as much of everyday life as possible.
Privacy-wise we also note that the complexity of data processes and the power of modern analytics drastically limit the awareness of individuals, their capability to evaluate the various consequences of their choices, and the expression of a real free and informed consent.[17] This lack of awareness is usually not avoided by giving adequate information to the individuals or by privacy policies, due to the fact that these notices are read only by a very limited number of users who, in many cases, are not able to understand part of the legal terms usually used in these notices, nor the consequences of consenting.[18]
An opportunity triggered by big data in relation to surveillance is the fact that comprehensiveness replaces comprehension. In other words, big data replaces detection with collection and lets the algorithm do the work. The whole population is monitored by allowing computers to detect anomalies and other patterns that correlate with suspicious activity. In this respect, it is important to remember that the purpose of monitoring is not eavesdropping on everyone.
Surveillance in big data furthermore contributes to preventive policing. Rather than starting with a suspect and then monitoring him or her, the goal is to start from generalised surveillance and then generate suspects.[19] This form of monitoring is not just for purposes of determent (for instance the placement of a surveillance camera in a notorious crime spot) but constitutes an actual strategy for intervention in the future through the use of modelling techniques.[20]
Applying this to the transport sector, ITS developments have given rise to car and in-car surveillance. This generates trails that are closely associated with individuals and which are available to various organisations. Crash cameras in cars, for example, could be imposed as a condition of purchase, insurance, or rental. Like so many other data trails, the data can be used for other purposes than originally intended (accident investigation), and with or without informed, freely given, and granular consent. In some countries, automatic number plate recognition (ANPR) has exceeded its nominal purpose of traffic management to provide vast mass transport surveillance databases.[21]
|
Illustration in the transport sector: More and more traffic control tools are becoming smart digital devices able to collect and process a high amount of (personal) data.[22] Some of them, such as red-light cameras or speed detectors, are used to enforce the law and to legally punish those who commit violations. However, the increasing number of traffic control tools allow for a much more substantial collection of personal data (e.g. parking meters, smart parking applications, automatic tolling systems, etc.). The processing and use of such personal data, for other purposes, would allow tracking individuals. Those data combined with personal data from other sources might give a very accurate image of individuals' social habits who might not have given their consent to those processing activities nor even be aware of them. |
'Free will' is defined by the Oxford English Dictionary as "the power of acting without the constraint of necessity or fate" or also "the ability to act at one's own discretion". It is an underlying principle to most, if not all, rights and freedoms enumerated in the EU Charter of Fundamental Rights. Of course, free will is no absolute given, just like the recitals of the EU Charter of Fundamental Rights state that enjoyment of the rights enshrined in the Charter "entails responsibilities and duties with regard to other persons, to the human community and to future generations".
Traditional deontological and utilitarian ethics place a strong emphasis on moral responsibility of the individual, often also called ‘moral agency’. This idea very much stems from assumptions about individualism and free will.[23] We note that these assumptions experience challenges in the era of big data, through the advancement of modern technology. In other words, big data as moral agency is being challenged on certain fundamental premises that most of the advancements in computer ethics took and still take for granted, namely free will and individualism.[24]
|
Illustration in the transport sector: Self-driving cars, by definition, monitor vehicles completely autonomously. This raises the ethical question of decision-making, especially in case of unavoidable impact.[25] The "Trolley Problem"[26] is often mentioned in this context: if a group of people is in the middle of the road and the self-driving car cannot stop because it is too fast, the car would have to choose between (i) driving into the group of people; (ii) driving into the pedestrian crossing the other lane (the pedestrian being for example an old lady or a young child); or (iii) ploughing into a wall and injuring or killing the driver and/or the passengers.[27] Such decisions can only be made by humans, and the decision-making results will differ between different persons. Creators will need to define algorithms to deal with these kinds of situations.[28] To address such types of moral dilemmas, the MIT Media Lab has developed a "Moral Machine"[29] to gather citizens' opinions about particular scenarios and share the results with car manufacturers and engineers who develop algorithms. This poll has reached millions of people who took part in the experiment. Interestingly, though not entirely unexpected, the results of the study show that moral choices may differ depending on geographic location and/or culture of the respondents.[30] |
With the current hyper-connected era of big data, the concept of power, which is so crucial for ethics and moral responsibility, is changing into a more networked concept. Big data stakeholders such as collectors, users, and generators of big data have relational power in the sense of a network.[31] In this regard, retaining the individual’s agency (i.e. knowledge and ability to act) is one of the main and complex challenges for the governance of socio-technical epistemic systems.[32]
Big data is the effect of individual actions, sensor data, and other real-world measurements creating a digital image of our reality, so-called "datafication".[33] The absence of knowledge about what data are collected or what they are used for might put the 'data generators' (e.g. online consumers and people owning handheld devices) at an ethical disadvantage in terms of free will. Many researchers[34] believe that big data causes a loss of free will and autonomy of humans by applying deterministic knowledge to human behaviour. Even the collection of anonymised data about individuals can lead to illegal behaviours in terms of free will of humans.[35] Indeed, aggregated and anonymised data could also be used to target individuals established on predictive models.[36]
With respect to supporting free will of humans, increasing accessibility and personalisation for passengers can provide benefits to people in the form of more personalised or affordable services. Organisations use certain data like journey data to ensure a better understanding and serving of people's needs.[37]
Furthermore, a huge part of what we know about the world, particularly about social and political phenomena, stems from analysis of data. This kind of insight can be extended into new domains by big data, which achieves greater accuracy in pinpointing individual behaviour, and the capability of generating this knowledge can be undertaken by new actors and more powerful tools.[38] Although a growing body of information being generated from big data provides a level that is imperceptible to individuals[39], various fields of IT such as information retrieval[40], user modelling and recommender system[41] have been studied to provide proper options for people.
With the changing role of data in transport, from data-poor to data-rich, big data in the field of transport is now accessible in new ways and at new scales. Companies are collecting higher volumes of this data, more frequently, and in real time – as technology makes this more feasible and viable – and are using such data to innovate. Customers expect more personalisation and communication as well as more real-time data being shared. Transport data can be used and shared to benefit businesses, people and public services, potentially in ways that meet the needs of all three groups.
Our next article will delve into a particular social and ethical issue that may materialise in a big data context, namely (data-driven) discrimination.
We would like to thank the Western Norway Research Institute for their valuable contributions, and in particular Rajendra Akerkar, Minsung Hong and Zuzana Nordeng.
 This series of articles has been made possible by the LeMO Project (www.lemo-h2020.eu), of which Bird & Bird LLP is a partner. The LeMO project has received funding from the European Union’s Horizon 2020 research and innovation programme under grant agreement no. 770038.
This series of articles has been made possible by the LeMO Project (www.lemo-h2020.eu), of which Bird & Bird LLP is a partner. The LeMO project has received funding from the European Union’s Horizon 2020 research and innovation programme under grant agreement no. 770038.
The information given in this document concerning technical, legal or professional subject matter is for guidance only and does not constitute legal or professional advice.
The content of this article reflects only the authors’ views. The European Commission and Innovation and Networks Executive Agency (INEA) are not responsible for any use that may be made of the information it contains.
[1] Akhil Mittal, 'Trustworthiness of Big Data' (2013) 80(9) International Journal of Computer Applications 35
[2] Shannon Vallor, Technology and the virtues: A philosophical guide to a future worth wanting (Oxford University Press 2016)
[3] Bart Custers and others, 'Deliverable 2.2 Lists of Ethical, Legal, Societal and Economic Issues of Big Data Technologies. Ethical and Societal Implications of Data Sciences' (e-SIDES, 2017) 33-34 <
[4] Johannes Sänger and others, 'Trust and Big Data: A Roadmap for Research' in Morvan F, Wagner R R and Tjoa A M (eds) 2014 25th International Workshop on Database and Expert Systems Applications (IEEE, 2014) 278-282, DOI: 10.1109/DEXA.2014.63
[5] Akhil Mittal, 'Trustworthiness of Big Data' (2013) 80(9) International Journal of Computer Applications 35
[6] Johannes Sänger and others, 'Trust and Big Data: A Roadmap for Research' in Morvan F, Wagner R R and Tjoa A M (eds) 2014 25th International Workshop on Database and Expert Systems Applications (IEEE, 2014) 278-282, DOI: 10.1109/DEXA.2014.63
[7] Cloud Security Alliance Big Data Working Group, Expanded top ten big data security and privacy challenges (White Paper, 2013)
[8] Xindong Wu and others, 'Data Mining with Big Data' (2014) 26(1) IEEE Transactions on Knowledge and Data Engineering 97
[9] Zijian Ming and others, 'BDGS: A Scalable Big Data Generator Suite in Big Data Benchmarking' in Tilmann Rabl and others (eds) Advancing Big Data Benchmarks (WBDB 2013, Lecture Notes in Computer Science, vol 8585, Springer, Cham)
[10] Akhil Mittal, 'Trustworthiness of Big Data' (2013) 80(9) International Journal of Computer Applications 35
[11] Junping Zhang and others, 'Data-driven Intelligent Transportation Systems: A Survey' (2011) 12(4) IEEE Transactions on Intelligent Transportation Systems 1624
[12] Aidin Ferdowsi, Ursula Challita and Walid Saad, 'Deep Learning for Reliable Mobile Edge Analytics in Intelligent Transportation Systems' (2017) abs/1712.04135 CoRR arXiv:1712.04135
[13] Mark Andrejevic, 'Surveillance in the Big Data Era' in Kenneth D. Pimple (ed) Emerging Pervasive Information and Communication Technologies (PICT) (Law, Governance and Technology Series, vol 11, Springer, Dordrecht, 2014) 55
[14] William Bogard, The Simulation of Surveillance: Hyper-control in Telematic Societies (Cambridge University Press 1996)
[15] Alessandro Mantelero and Giuseppe Vaciago, 'The “Dark Side” of Big Data: Private and Public Interaction in Social Surveillance' (2013) 14(6) Computer Law Review International 161
[16] Andrejevic, 'Surveillance in the Big Data Era' in Kenneth D. Pimple (ed) Emerging Pervasive Information and Communication Technologies (PICT) (Law, Governance and Technology Series, vol 11, Springer, Dordrecht, 2014) 55
[17] Laura Brandimarte, Alessandro Acquisti and George Loewenstein, 'Misplaced Confidences: Privacy and the Control Paradox' (2013) 4(3) Social Psychological and Personality Science 340
[18] Joseph Turow and others, 'The Federal Trade Commission and Consumer Privacy in the Coming Decade' (2007) 3 ISJLP 723
[19] Ibid
[20] William Bogard, The Simulation of Surveillance: Hyper-control in Telematic Societies (Cambridge University Press 1996)
[21] Marcus R. Wigan, and Roger Clarke, 'Big Data's Big Unintended Consequences' (2013) 46(6) Computer 46
[22] Jaimee Lederman, Brian D. Taylor and Mark Garrett, 'A Private Matter: The Implication of Privacy Regulations for Intelligent Transportation Systems' (2016) 39(2) Transportation Planning and Technology 115
[23] Alasdair MacIntyre, A Short History of Ethics: A History of Moral Philosophy from the Homeric Age to the 20th Century (Routledge 2003)
[24] Andrej Zwitter, 'Big Data Ethics' (2014) 1(2) Big Data & Society 1
[25] EDPS, Opinion 4/2015
[26] Molly Crocket, 'The Trolley Problem: Would you Kill one Person to Save many Others?' The Guardian (12 December 2016) <https://www.theguardian.com/science/head-quarters/2016/dec/12/the-trolley-problem-would-you-kill-one-person-to-save-many-others> accessed 23 August 2018
[27] Tobias Holstein T, Dodig-Crnkovic G and Pelliccione P, 'Ethical and Social Aspects of Self-Driving Cars' (2018) abs/1802.04103 CoRR arXiv:1802.04103
[28] Caitlin A. Surakitbanharn and others, 'Preliminary Ethical, Legal and Social Implications of Connected and Autonomous Transportation Vehicles' <https://www.purdue.edu/discoverypark/ppri/docs/Literature%20Review_CATV.pdf> accessed 23 August 2018
[30] Edmond Awad, Sohan Dsouza, Richard Kim, Jonathan Schulz, Joseph Henrich, Azim Shariff, Jean-François Bonnefon & Iyad Rahwan, 'The Moral Machine experiment', Nature volume 563, 59–64 (24 October 2018), <https://www.nature.com/articles/s41586-018-0637-6> accessed 12 April 2019
[31] Robert A. Hanneman and Mark Riddle, Introduction to Social Network Methods (University of California 2005)
[32] Judith Simon, 'Distributed Epistemic Responsibility in a Hyperconnected Era' in Luciano Floridi (ed) The Onlife Manifesto (Springer, Cham, 2015)
[33] Kenneth Cukier, 'Big Data is Better Data' (TED 2014) <https://www.youtube.com/watch?v=8pHzROP1D-w> accessed 23 August 2018
[34] Chris Snijders, Uwe Matzat and Ulf-Dietrich Reips, '"Big Data": Big Gaps of Knowledge in the Field of Internet Science' (2012) 7(1) International Journal of Internet Science 1
[35] Sciencewise Expert Resource Centre 'Big Data: Public Views on the Collection, Sharing and Use of Personal Data by Government and Companies' (Sciencewise 2014)
[36] Charles Duhigg, 'How Companies Learn your Secrets' The New York Times (New York, 19 February 2012) 30
[37] Libby Young and others, 'Personal Data in Transport: Exploring a Framework for the Future' (Open Data Institute 2018) <
[38] Larisa Giber and Nikolai Kazantsev, 'The Ethics of Big Data: Analytical Survey' (2015) 2(3) Cloud of science 400
[39] Ralph Schroeder and Josh Cowls, 'Big Data, Ethics, and the Social Implications of Knowledge Production' (Data Ethics Workshop, KDD@Bloomberg, New York, 2014) <https://pdfs.semanticscholar.org/5010/f3927ca8133a432ac1d12a8e57ac11cb3688.pdf> accessed 23 August 2018
[40] Beth Plale, 'Big Data Opportunities and Challenges for IR, Text Mining and NLP' in Xiaozhong Liu and others (eds) Proceedings of the 2013 International Workshop on Mining Unstructured Big Data Using Natural Language Processing (ACM, 2013) DOI: 10.1145/2513549.2514739
[41] Fatima EL Jamiy and others, 'The Potential and Challenges of Big Data - Recommendation Systems Next Level Application' (2015) arXiv:1501.03424v1 accessed 23 August 2018



{kind=link}